
I recently added our company website as a ‘public website’ source. Almost immediately, we were hit by 50mb/s of traffic for several minutes, which nearly took the whole site down.
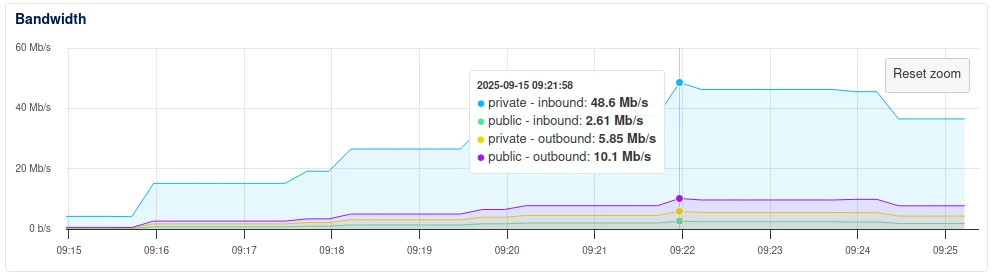
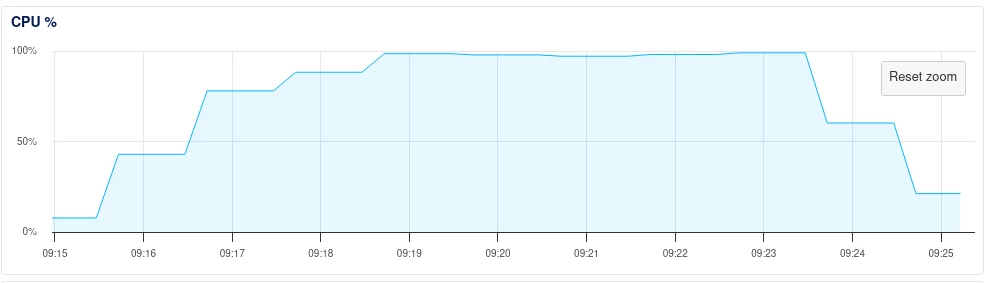
I would like a way to throttle and direct these content grabs, as a naive crawl would seem to be pulling in multiple versions of each page (despite us having canonical meta tags), and we only really want a certain part of the site scanned. Furthermore, I would like to ensure that a crawl does not put undue pressure upon it
I contacted official support about this and after being initially responsive (although of not much use) they just ignored me. Laughably, they asked for feedback a few days later, and even though I provided the worst score I could I haven’t heard anything back from that.
I also asked if there was a way for us to integrate an MCP source, which may prove more useful, and that question was also ignored.
Is there anyone here who can help?
thanks very much in advance.
Adam


