How to get Link Header in response from Search for Cards?
I’m using the Try It! tool in the API Reference to test the results of a card search. My search should return more than 50 cards that match my search term. I’m trying to figure out how to get the Link Header indicating another page of search results exists.
My URL is “"https://api.getguru.com/api/v1/search/query?searchTerms=filters&queryType=cards&showArchived=false&maxResults=50&includeCardAttributes=false"”
Is there an example of how to get search results and page thru them?
Page 1 / 1
Hi @Chris Adams
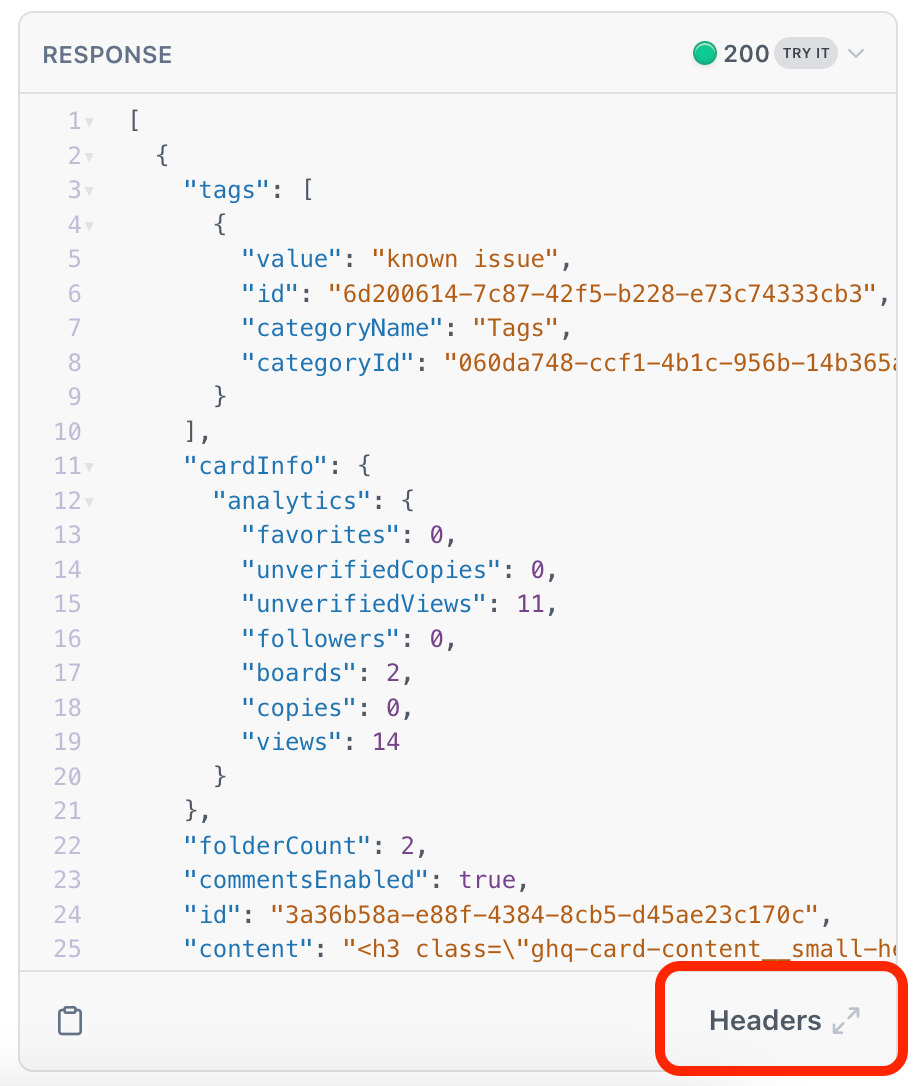
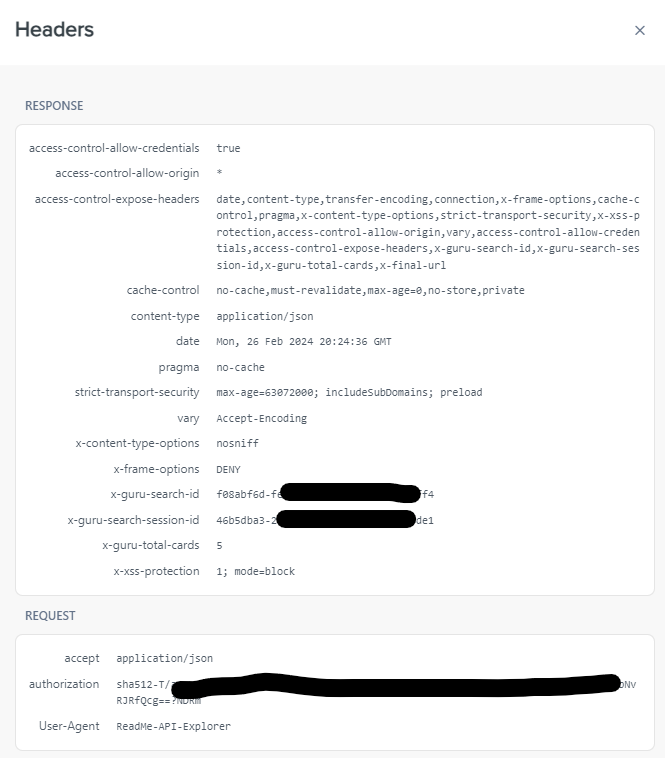
When using the Try It! functionality, you should see a “Headers” button below the response - by clicking that button, you should be able to see your response headers. The response header that you’re looking for is called “link”. You’ll want to copy everything between the angle brackets and call that URL to get the next page. The URL contains the token.
Let me know if this works for you!
I checked that. Below is the header data that I’m getting. Should one of the responses be ‘link’ or would it be embedded in one of the responses?
@Chris Adams ah - I believe you need to remove the &maxResults=50 parameter from the URL. We generally automatically cap each response page at 50 records (higher for a few endpoints). By including that URL parameter, you’re telling our server to only return 50 records which is why you’re not seeing the link header in the response.
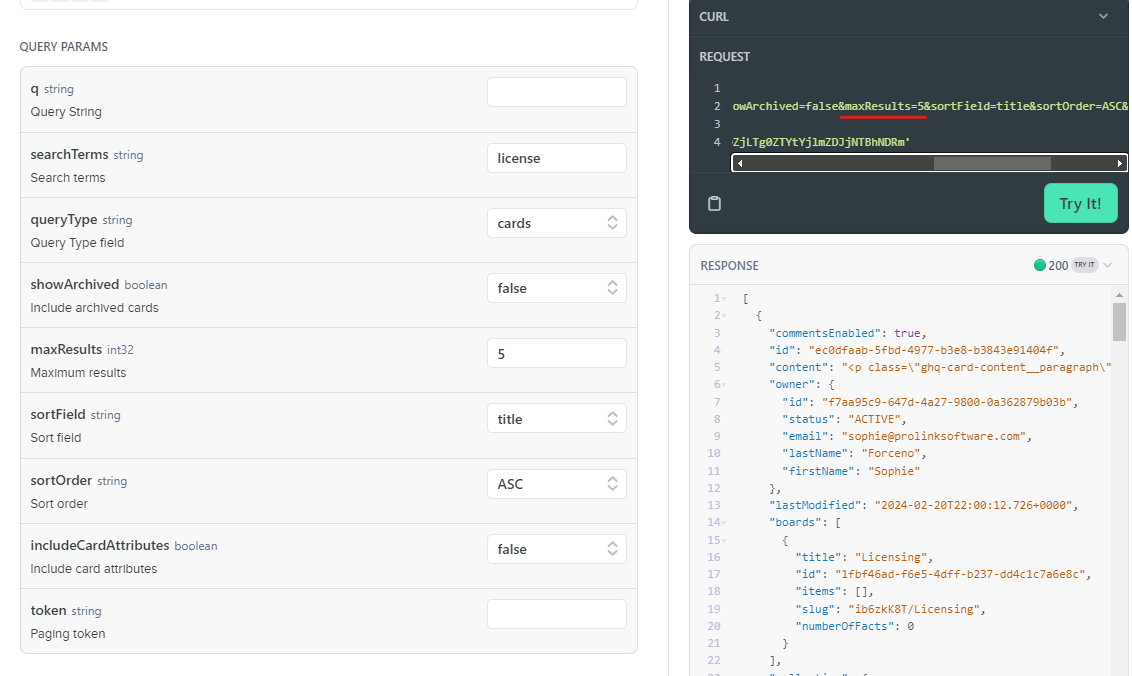
Setting the maxResults failed to help. I set maxResults=5 to be sure that results would be paged. Below are the parameters that I used and the results.
Below was ‘search/query’. Using ‘cardmgr’ had similar results and link was not in the header. BTW, what is the difference between
Raw header retrieved by my Python program executing this web service call…
Hey @Chris Adams - after speaking with a couple of our engineers, it sounds like we do not support paging through keyword search results. Apologies for leading you astray here - I’ll be updating our documentation to reflect this.
Here is some context as to why this is not currently possible. In the Guru UI, if you were to search for cards in the search bar, we return up to 50 cards. The ability to page past the 50th card in the result set does not exist in the UI. This is because they are ordered in terms of relevance, and by the time you get to the bottom of that list of 50, its very unlikely those cards are relevant to what you’re searching for.
If you could give me some more detail around what you’re attempting to build with our API, I may be able to suggest an alternate route.
@Joe Duffy Thanks for the update. I feel better that I was not missing something.
Now, my challenge is how do I get more than 50 articles that match a user’s search criteria? Pease share if you have suggestions. (BTW, if it is a concern about the amount of data being returned, then all I need is the card’s id and preferredPhrase.)
Hi @Chris Adams - understanding a bit more around what you’re trying to build out would help me in suggesting something. Is there anything more you’re able to share around what the end goal is?
@Joe Duffy
My employer develops a suite of software for Manufacturing quality control. We are migrating our public facing knowledge base articles from our website's database to Guru. Presently, we have 600 articles in our KB repository in HTML format and 50 in PDF and DOC format. The new Guru collection will consolidate all articles into the same format, so customers can finally search all articles.
I have a python program that migrates our HTML articles to a Guru collection. This program extracts HTML and images from our SQL database and creates cards and attachments to reconstruct the article in Guru.
The next step is creating a web page that will get search the cards in our customer KB article collection. The customer enters search term(s). These term(s) will be used in a Guru search API to get an array of matching cards. Then the page will list the card titles and ideally with the first 100 characters of each article. The customer will select a title. This redirect to a display page. The display page will call the Guru API to get the article by GUID. The card content will be display in web page on our site.
I have a working prototype search and display page. The 50 item limit is problematic. To mitigate this limitation, we are doing 2 things. First, the search terms will be modified to be in the format of f"term1" AND "term2" AND...]. Thru experimentation, we learned this format instructs the Guru search engine to return cards with 'all' search terms since it trigger (classic AND Boolean logic). Next, the search page will put instructions in a tool tip and at the bottom of the results instructing the customer to carefully choose their search terms.
Future page enhancements will be filtering results by last modified date or other criteria.
@Chris Adams - this is great info - thanks for sharing!
Regarding the 50 item limit, I'm curious to understand more about how this impacts your specific use case. We have this limit in place within our own UI to ensure optimal performance and user experience, and we've found that, thanks to our search algorithm, users can usually find the most relevant information right at the top of their search results. Our algorithm also doesn’t require users to carefully choose their search terms.
It's great to hear that you're experimenting with search term formats to refine the results. Our search functionality is designed to be robust, aiming to bring the most relevant cards to the top. To help you and your team get the most out of our search capabilities, I’ve linked a few resources from our Help Center that might offer some additional insights and tips:
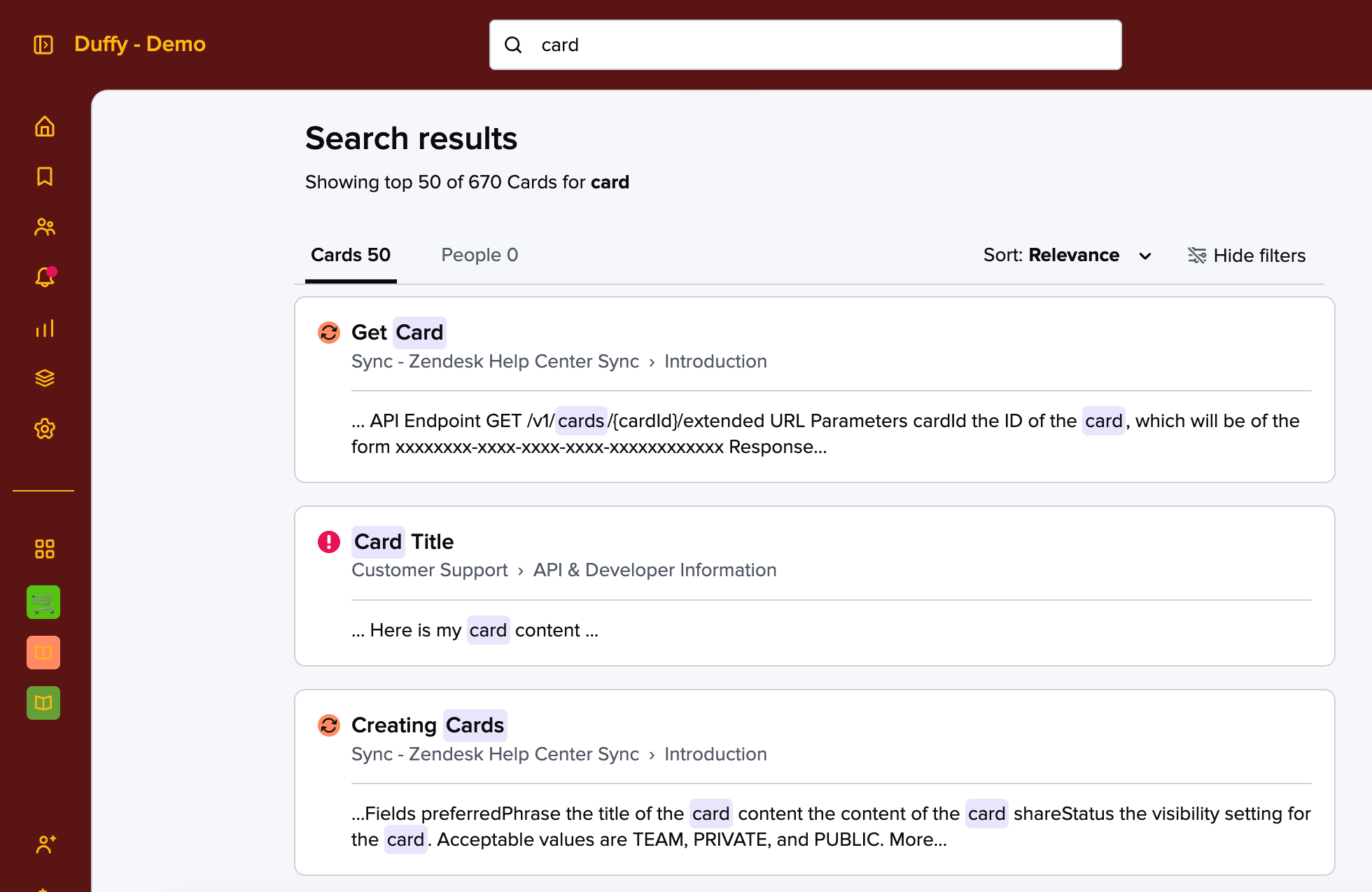
One thing that may help you is that when a user includes searchTerms, our API response includes fields such as highlightedTitleContent and highlightedBodyContent. These are the search results fields that are displayed to users in our UI - it includes highlighted content based on what they searched for. This might be helpful to you to display on your external site. I know you said you’d like to display the first 100 characters, but the highlightedBodyContent displays up to 200 characters, centered around terms in the card that are relevant to the search. Here’s a visual example of the search results with highlights when I search for the word “card”:
I hope you find this helpful and looking forward to your response!
@Joe Duffy Thanks this info will definitely be useful to improve our solution.
Our challenge is users often search on terms that are in more than 50 articles. It would be desirable to page thru bundles articles as the original search API documentation had suggested.
FYI Guru Team - it has been 5 months since this thread and your API documentation has still not been updated. It still claims that there is a “Link” header that will appear in the returned payload if there are more than 50 cards returned.
Anyway, I would like help with my use case. My big picture goal is to obtain all Guru cards within a particular collection and upload the the content as articles to a another service my Company is using. I have run a Get call to the https://api.getguru.com/api/v1/search/cardmgr endpoint with a query parameter of “searchTerms” and and as expected, only 50 items in the array are returned. This particular collection has 612 cards. So my question is how can i obtain the content of every card in this collection (if the limit returned through the Search endpoint is 50)?
Hi @Ammon Orgill
If you want to get every card that lives in a collection, you can still use the POST/api/v1/search/query endpoint. Here is what you would pass in the body: